Last week, our CMO shared an interesting insight: “We should team up with [...] They come up in 70% of our sales calls.”
This caught our attention because just a few years ago, figuring this out would've required hours of call recording analysis. Now, with tools designed and powered by AI & NLP (Natural Language Processing), we can quickly analyze data from every customer meeting and make informed decisions.
It's a glimpse into how large language models are changing the way we use technology.
Large Language Model’s (LLM)
NLP (Natural Language Processing) is not something new; however, there has been tremendous progress during the past five years as a result of deepening in use of deep neural networks. They are a new type of network, and they have been trained with large amounts of text. The training makes it possible for them to understand, summarize and write text on their own.
Parameters are a model’s internal variables that drive its decision-making, similar to neurons in the brain. With more parameters, the model can increase its complexes and sophistication. The chart below demonstrates the expansion of models in just four years, from humble BERT with its mere 240 million parameters to colossal GPT-3 boasting of 175 billion.
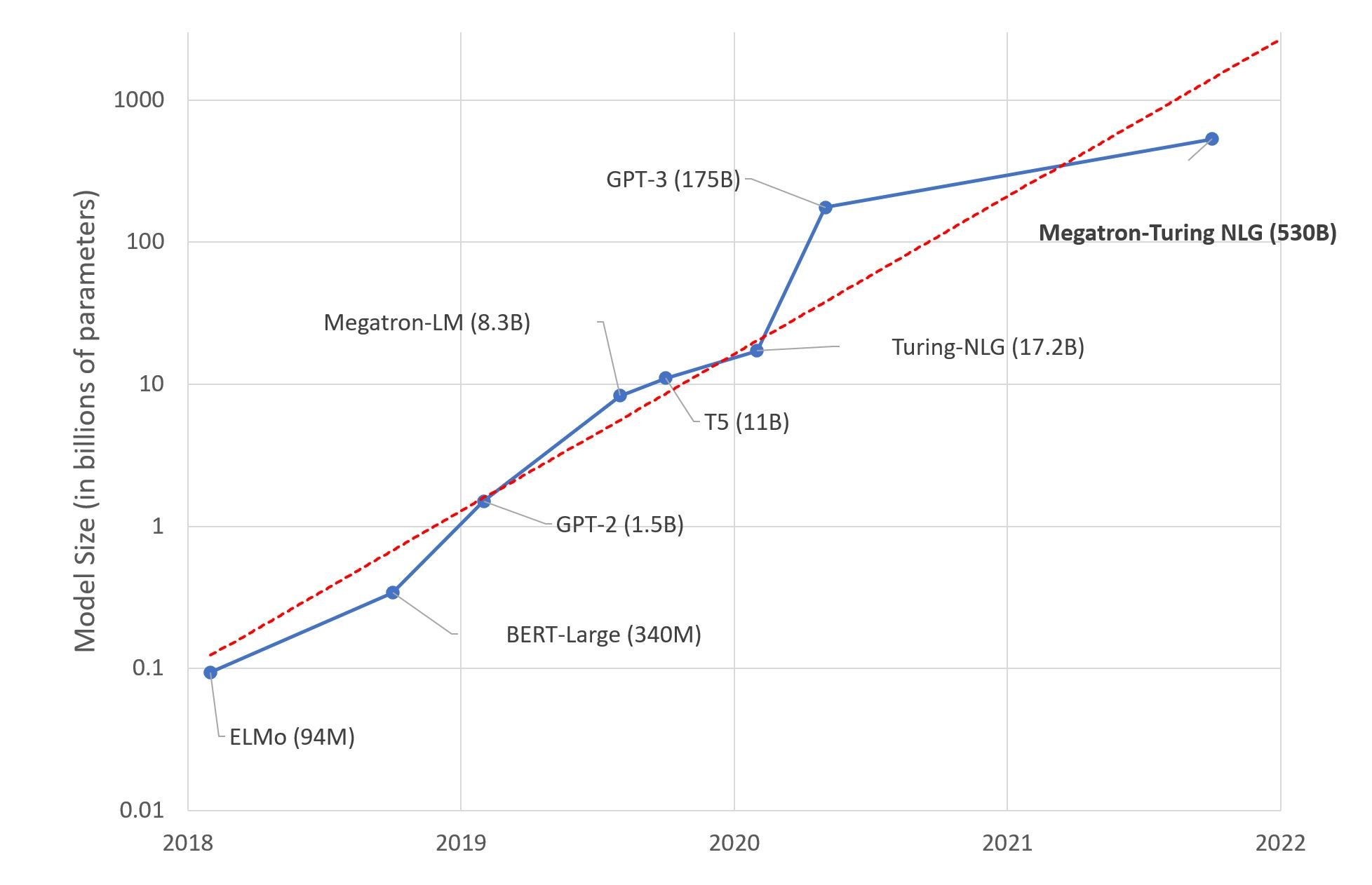
In our view, open-source models will rule the Large Language Model (LLM) domain, leaving proprietary ones in the dust, especially LLaMA 2.
LLaMA 2 outperforms foundational models such as GPT-3 and is competitive with PaLM, despite having 10 times fewer parameters. LLaMA 2 versions with sets of language models ranging from 7 billion to 70 billion parameters in size.
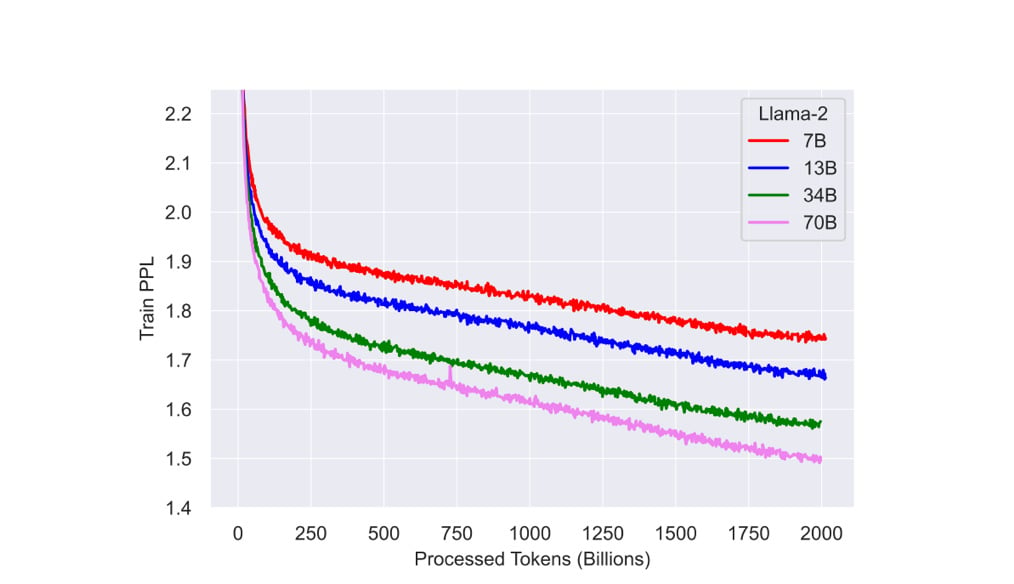
The graph above shows that large language models with fewer parameters than foundational ones such as GPT-3 or PaLM, like LLaMA2 7B (the version with 7 billion parameters), can outperform them if provided with more training.
The datasets LLaMA uses contain 1.4 trillion tokens from public sources such as GitHub, Wikipedia, arXiv and Stack Exchange. The tokenization process used byte-pair encoding, using SentencePiece software.
In another investment, rival, another Tech giant –Amazon invested an enormous $4B on Anthropic, which is almost as powerful as ChatGPT. The first of such was the establishment of a $1.25 billion venture that created a stir in Silicon Valley.
Oddly, Anthropic, a start-up of only two years, will be taking advantage of the power of Amazon’s AWS custom chips to speed up its AI software.
Applications Empowered by Large Language Models (LLMs)
Developing new language models costs a lot of money with many big players such as openAI, Google and Nvidia, among two others, controlling it. However, recently we have observed an outburst of several start-ups that utilize large preexisting language models to create numerous applications such as copywriting platforms or tools for programmers
With these, applications can now enter new areas never known before. Start-ups such as Jasper and Copy-A’I use, for example, LLMs to create a marketing text based only on some input topics. Autogenerated copy, on the other hand, signifies an entirely new product sphere as compared to the old approach, when writers would have nothing but fundamental tools at their disposal if they wanted to write from scratch.
Text to Image:
One recent internet sensation in the realm of LLM applications is DALL·E 2, an OpenAI creation capable of crafting realistic images and art based on short text prompts. For example, you could start with something like “an engineer eating a sandwich while making a painting of a walnut tree on an offshore rig”, and it will return just such an image.
A prompt given to DALL·E 2 was, ”Surreal painting of a child dreaming about floating among stars, using soft, dreamy colors and elements of fantasy”, and here's the result it generated.

Healthcare:
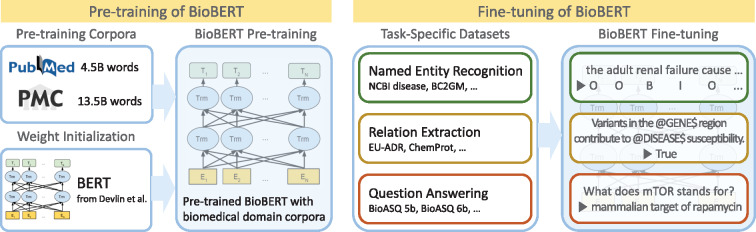
BioBERT (a pre-trained biomedical language representation model for biomedical text mining), a specialized language model for biomedicine derived from the BERT framework, has undergone further refinement using extensive biomedical datasets, encompassing PubMed summaries and PMC comprehensive.
This enhancement has resulted in notable progress in biomedical natural language processing activities, including:
- Pinpointing specific entities
- Discerning relationships
- Addressing queries
Finance:
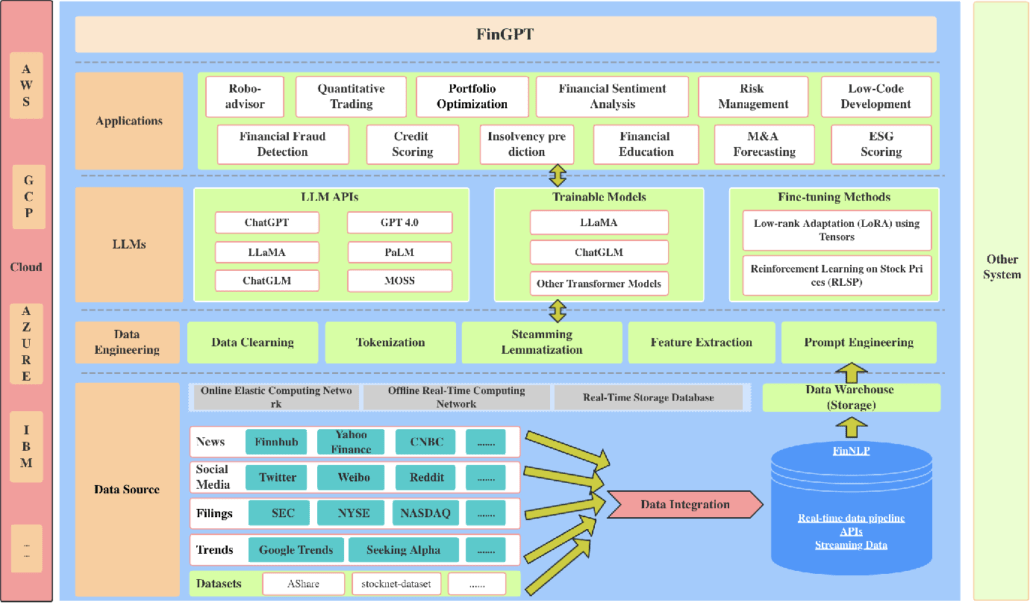
Applications of Large Language Models (LLMs) in the finance industry have gained significant traction in recent years. LLMs, such as GPT-4, BERT, RoBERTa, and specialized models like BloombergGPT, have demonstrated their potential to revolutionize various aspects of the fintech sector. These cutting-edge technologies offer several benefits and opportunities for both businesses and individuals within the finance industry.
- Fraud detection and prevention
- Risk assessment and management
- Personalized customer service
- Advanced financial advice
- News analysis and sentiment detection
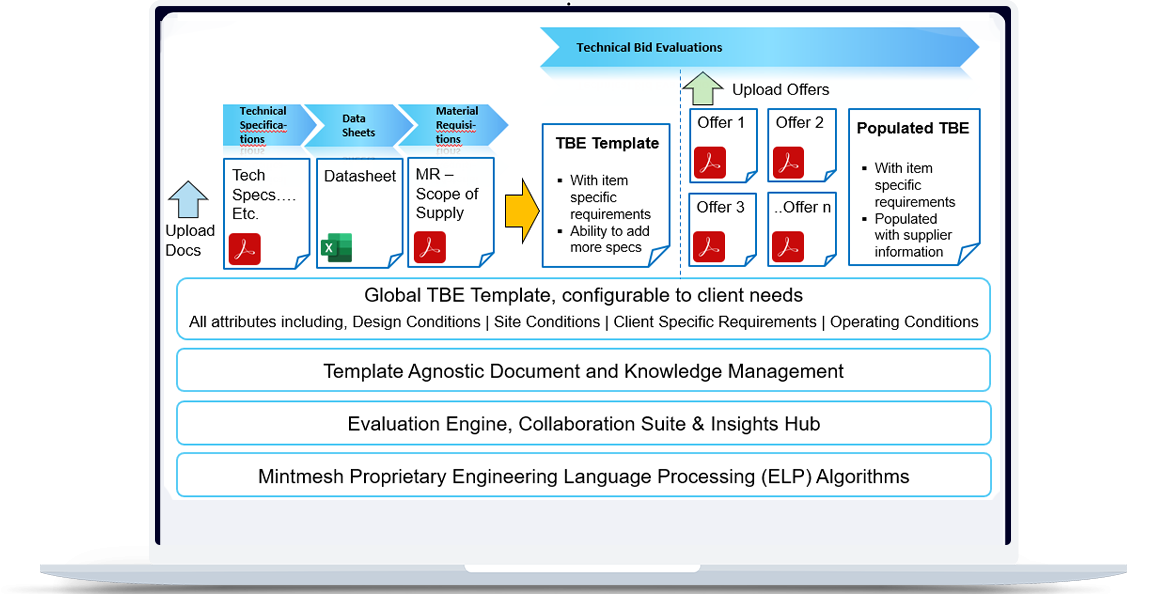
Engineering, Procurement & Construction:
Mintmesh’s RUDY has changed the face of EPC engineering when it was released in 2020 and reduced the time taken for the technical bid evaluation from hours to minutes that would be considered for historical years.
Several engineers, even very senior ones, we talked to admit that the NLP driven platform is a revolutionary tool and that they see a revolution taking place. To be sure, just many years ago, LLM did not participate actively in the fundamental technical bid evaluation process.
As a Knowledge Management hub, it becomes a single system of record with all requirements, offers, technical queries, collaboration timeline, supplier scorecard & relevant eta-data per item bid tab. Engineers can search, analyze & refer to this information for future projects.
What’s Next in Large Language Models (LLMs) for B2B
Historically, there’s always a question when you have market dislocations. What happens to the jobs? What happens to people?
To quote, Andreessen Horowitz (aka a16z), the answer lies in Jevons Paradox.
Jevons Paradox is if the demand is elastic, even if you drop the price, the demand will more than make up for it.
In terms of creation and work automation, the appetite for output is flexible. The way we see it, the more we produce, the more people will consume. We're eagerly anticipating a substantial surge in productivity, the emergence of numerous new job opportunities, and a host of fresh developments. We believe it will unfold much like the evolution of the microchip and the internet.
With LLMs, applications are enabled to preserve immense information and context that can easily provide the required facts presented in an ordinary manner. From refining customer support to revolutionizing content creation and advancing data analysis, the potential applications of LLMs are vast and promising. The power of these language models to comprehend, generate, and contextualize information is propelling B2B software into a new era of efficiency and innovation.
Embracing this technology is not merely an option; it's a strategic necessity for businesses striving to stay competitive and relevant in an ever-evolving digital world. The future of B2B software is intricately linked with the advancements and integration of Large Language Models, and the journey ahead is indeed one to watch with eager anticipation.
Check out our in-depth page on Artificial Intelligence for EPC, their variations and actual use cases for the Engineering, Procurement and Construction sector.